
How an LLM Learns Who You Are: An Anatomy of Persistent Memory in AI Agents
How an LLM Learns Who You Are: An Anatomy of Persistent Memory in AI Agents
When ChatGPT remembers you're vegetarian, or when your AI assistant pulls up a project you mentioned three weeks ago, something feels different. The model knows you. That, at least, is the illusion.
This article is about what's actually happening underneath. Because the truth is that LLMs are completely stateless. Every request to a language model is, from the model's perspective, the first request it has ever seen. There is no persistent state inside the network. No accumulated experience. No memory of yesterday.
Everything you perceive as the model knowing you is engineering. Memory in AI agents is not a property of the model. It is a system built around the model that creates a convincing illusion of continuity.
This piece anatomizes that system. We'll walk through the four core problems any memory architecture must solve, compare the four dominant patterns in use today, with real code and measured tradeoffs, and end with the genuinely hard problems that nobody has fully cracked yet.
1. The Statelessness Premise
To talk about memory in LLMs honestly, we need to be precise about what's happening.
A language model is a function. You hand it a sequence of tokens, it returns a probability distribution over the next token. Run that loop and you get a response. The model holds no information between calls. Two requests to the same model from the same user, five seconds apart, are indistinguishable to the model itself.
What you experience as a continuous conversation is just the client sending the entire conversation history back to the model on every turn. The model isn't remembering the conversation. It's re-reading it from scratch, every time, and pretending it remembers.
This is fine for a single session. The context window holds the whole exchange. But the moment a session ends, that conversation is gone from the model's perspective. If you want the assistant to remember you next week, next month, or next year, you need to build that memory outside the model.
This is where the engineering starts.
2. The Four Core Problems
Any persistent memory system, regardless of architecture, has to solve four problems. Get any one of them wrong and the whole illusion collapses.
Extraction. What is worth remembering from a conversation? Every word? Only the facts? The emotions? Decisions? Preferences? You're processing a stream of tokens and you need to decide what to write down. Store too much and you'll drown in noise. Store too little and you'll miss the things that mattered.
Storage. Once you've decided what to remember, how do you represent it? Raw text? Embeddings? Structured records? A graph? Each choice has consequences. Storage format determines what retrieval is even possible later.
Retrieval. At the moment a new conversation starts, how does the system know which memories are relevant? You can't dump everything into the context window. You need a function that takes the current situation and returns the right slice of history. Wrong retrieval means the model either misses something important or gets distracted by irrelevant noise.
Application. Finally, once you have the right memories, how do you inject them into the prompt without confusing the model? Memories are not just information. They're context that shapes how the model interprets the rest of the input. The way you frame a memory can be as important as the memory itself.
These four problems are not independent. A decision in extraction constrains what's possible in retrieval. A choice in storage limits the application strategies available. Memory architectures are fundamentally about how these four problems get coupled.
3. Four Architectural Patterns
We'll walk through four patterns in order of complexity, from the simplest production approach to the most sophisticated.
Pattern 1: Flat Log with Vector Search
This is the workhorse. It powers most "memory" features you've used. The idea is straightforward: store every interaction as a chunk of text, embed each chunk into a vector, and retrieve by semantic similarity when needed.
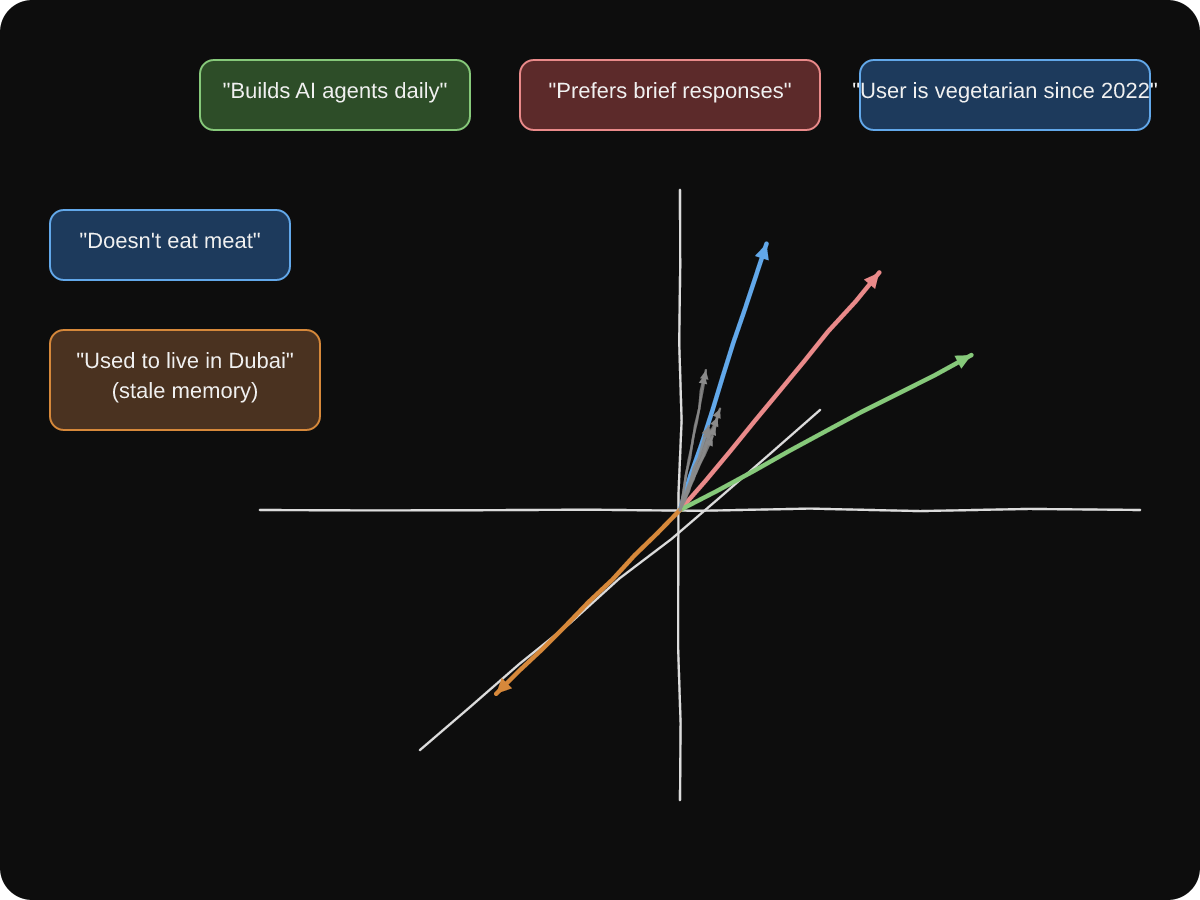 Figure 1: Each memory becomes a vector in a high-dimensional space. The colored arrows represent different memory categories, and the cluster of grey arrows around the blue vector represents semantically similar memories that align in the same direction.
Figure 1: Each memory becomes a vector in a high-dimensional space. The colored arrows represent different memory categories, and the cluster of grey arrows around the blue vector represents semantically similar memories that align in the same direction.
The extraction is trivial. You just store everything, or you store summaries of each conversation. Storage is a vector database. Retrieval is k-nearest-neighbor search. Application is injecting the top results into the prompt.
from openai import OpenAIimport chromadbclient = OpenAI()db = chromadb.Client().get_or_create_collection("user_memory")def remember(user_id: str, text: str, metadata: dict = None): embedding = client.embeddings.create( input=text, model="text-embedding-3-small" ).data[0].embedding db.add( ids=[f"{user_id}:{hash(text)}"], embeddings=[embedding], documents=[text], metadatas=[{**(metadata or {}), "user_id": user_id}] )def recall(user_id: str, query: str, k: int = 5) -> list[str]: query_emb = client.embeddings.create( input=query, model="text-embedding-3-small" ).data[0].embedding results = db.query( query_embeddings=[query_emb], n_results=k, where={"user_id": user_id} ) return results["documents"][0]def chat_with_memory(user_id: str, user_message: str): memories = recall(user_id, user_message) context = "\n".join(f"- {m}" for m in memories) response = client.chat.completions.create( model="gpt-4o", messages=[ {"role": "system", "content": f"You know the following about the user:\n{context}"}, {"role": "user", "content": user_message} ] ) return response.choices[0].message.contentThe strength of this approach is that it's simple to build, easy to scale, and works reasonably well out of the box. The weakness is that it has no notion of structure. Asking "where does the user live?" and "what city does the user live in?" might retrieve completely different memories. The system doesn't know these are the same question. And it has no way to handle contradictions. If you said "I live in Amman" six months ago and "I just moved to Dubai" yesterday, semantic search might return both. The model then has to figure out which one is current.
Use when: you need something working fast, conversations are long and varied, and approximate recall is acceptable.
Pattern 2: Structured Profile Extraction
Instead of storing raw text, this pattern uses the LLM itself to extract facts from conversations and maintain a structured profile of the user.
from pydantic import BaseModelfrom typing import Optional, Literalimport jsonclass UserProfile(BaseModel): name: Optional[str] = None location: Optional[str] = None occupation: Optional[str] = None dietary_restrictions: list[str] = [] communication_style: Optional[Literal["formal", "casual", "technical"]] = None interests: list[str] = [] current_projects: list[dict] = []EXTRACTION_PROMPT = """You are a memory extraction system. Given a conversation and the user's current profile,return an updated profile reflecting any new information learned. Only modify fields ifthe conversation provides clear new information. Return valid JSON matching the schema.Current profile:{profile}New conversation:{conversation}Return the updated profile as JSON."""def update_profile(profile: UserProfile, conversation: str) -> UserProfile: response = client.chat.completions.create( model="gpt-4o", messages=[{ "role": "user", "content": EXTRACTION_PROMPT.format( profile=profile.model_dump_json(indent=2), conversation=conversation ) }], response_format={"type": "json_object"} ) updated_data = json.loads(response.choices[0].message.content) return UserProfile(**updated_data)def chat_with_profile(profile: UserProfile, user_message: str): response = client.chat.completions.create( model="gpt-4o", messages=[ {"role": "system", "content": f"User profile:\n{profile.model_dump_json(indent=2)}"}, {"role": "user", "content": user_message} ] ) return response.choices[0].message.contentThe strength here is precision. The model gets a clean, structured picture of the user, not a noisy bag of retrieved snippets. There's no ambiguity about what the system knows. Contradictions are resolved at write time, when the extractor updates a field, rather than at read time when the model has to reconcile conflicting memories.
The weakness is the schema. You have to decide upfront what kinds of facts matter. If a user starts talking about something that doesn't fit your schema, that information is lost. And the extraction step itself can hallucinate, inferring "facts" the user never actually stated.
Use when: the use case is narrow enough that you can predict the relevant fact types, and precision matters more than coverage.
Pattern 3: Hierarchical Memory (MemGPT-Style)
Packer et al. (2023) introduced the idea of treating an LLM's context window like RAM in an operating system. The model itself decides what to swap into the working context and what to push out to slower storage. This was published as MemGPT and later productized as Letta.
The architecture has three tiers. The main context is what the model sees on every request, including a small block of "core memory" with the user's most important facts. Recall storage holds the conversation history that's been swept out of context but is still searchable. Archival storage is for arbitrary documents and long-term knowledge.
The model has function-calling access to these tiers. It can rewrite its own core memory when it learns something important. It can search recall when it needs to remember a past conversation. It can write to and read from archival when working with documents.
CORE_MEMORY_TEMPLATE = """=== Core Memory ===[Persona]{persona}[User]{user_block}[Active Context]{active_context}"""TOOLS = [ { "type": "function", "function": { "name": "core_memory_replace", "description": "Rewrite a section of core memory.", "parameters": { "type": "object", "properties": { "section": {"enum": ["persona", "user_block", "active_context"]}, "old_text": {"type": "string"}, "new_text": {"type": "string"} } } } }, { "type": "function", "function": { "name": "recall_search", "description": "Search past conversations.", "parameters": { "type": "object", "properties": {"query": {"type": "string"}} } } }, { "type": "function", "function": { "name": "archival_insert", "description": "Store a piece of information in long-term archival memory.", "parameters": { "type": "object", "properties": {"content": {"type": "string"}} } } }]def agent_step(state: dict, user_message: str): system_prompt = CORE_MEMORY_TEMPLATE.format(**state["core_memory"]) response = client.chat.completions.create( model="gpt-4o", messages=[ {"role": "system", "content": system_prompt}, *state["working_messages"], {"role": "user", "content": user_message} ], tools=TOOLS ) return handle_response(state, response)The strength is that the model becomes an active participant in managing its own memory. It learns to summarize, prioritize, and update. This sidesteps the schema problem in Pattern 2 because the model decides what's worth keeping, not you.
The weakness is reliability. The model is making memory management decisions on every turn, and those decisions cost tokens, latency, and money. It can also make bad decisions, overwriting useful context or forgetting to write down something it should have. Production systems built on this pattern usually add guardrails: explicit confirmation steps, periodic memory audits, or schema constraints on the core memory.
Use when: you're building a long-running agent that needs to genuinely adapt to a user over months, and you can absorb the additional token cost of self-managed memory.
Pattern 4: Knowledge Graph Memory
This is the pattern that treats memories as a graph of entities and relationships. Park et al. (2023) used a variant of this in Generative Agents, the Stanford paper that simulated a small town of LLM-powered characters. Each character maintained a memory stream where individual observations were scored by importance, recency, and relevance, and reflection events synthesized higher-level insights from clusters of related memories.
The production version of this idea uses an actual graph database. Each piece of information becomes a node or an edge. Querying the graph traverses relationships instead of doing semantic search.
from neo4j import GraphDatabasedriver = GraphDatabase.driver("bolt://localhost:7687")EXTRACTION_PROMPT = """Extract entities and relationships from this conversation snippet.Return JSON in the format:{{ "entities": [{{"name": ..., "type": ...}}], "relationships": [{{"from": ..., "type": ..., "to": ..., "metadata": {{...}}}}]}}Conversation: {text}"""def ingest(user_id: str, text: str): extraction = json.loads(client.chat.completions.create( model="gpt-4o", messages=[{"role": "user", "content": EXTRACTION_PROMPT.format(text=text)}], response_format={"type": "json_object"} ).choices[0].message.content) with driver.session() as session: for entity in extraction["entities"]: session.run( "MERGE (e:Entity {name: $name, type: $type, user_id: $uid})", name=entity["name"], type=entity["type"], uid=user_id ) for rel in extraction["relationships"]: session.run( """ MATCH (a:Entity {name: $from_name, user_id: $uid}) MATCH (b:Entity {name: $to_name, user_id: $uid}) MERGE (a)-[r:RELATES {type: $rel_type}]->(b) SET r += $metadata """, from_name=rel["from"], to_name=rel["to"], rel_type=rel["type"], uid=user_id, metadata=rel.get("metadata", {}) )def query_neighborhood(user_id: str, entity_name: str, depth: int = 2): with driver.session() as session: result = session.run( f""" MATCH path = (e:Entity {{name: $name, user_id: $uid}})-[*1..{depth}]-(related) RETURN path """, name=entity_name, uid=user_id ) return [record["path"] for record in result]The strength of the graph approach is that it captures structure that pure embeddings miss. The fact that "Sara is the user's sister" and "Sara works at Google" become connected facts. Asking "where does the user's sister work?" can be answered by traversing the graph, even if no single past message contained that exact phrasing.
The weakness is the extraction step. Getting entities and relationships right is hard. The same person mentioned across different conversations needs to be resolved to the same node (the entity resolution problem). Relationship types proliferate if not constrained. And graph queries don't degrade gracefully. If the graph is missing the right edge, you get nothing back, where vector search would at least return something approximately relevant.
Use when: the domain has clear relational structure that matters, and you have the engineering budget to handle entity resolution properly.
4. Quick Comparison
| Pattern | Extraction cost | Retrieval quality | Handles contradictions | Best for |
|---|---|---|---|---|
| Flat log + vectors | None | Approximate | Poorly | Quick start, broad coverage |
| Structured profile | Per-conversation LLM call | Exact | At write time | Narrow domains, precision |
| Hierarchical (MemGPT) | Per-turn LLM cost | Active | Model decides | Long-running agents |
| Knowledge graph | Heavy extraction | Structured | Via versioning | Relational data |
In production, the strongest systems are usually hybrids. Mem0, for instance, combines a vector store for raw recall with a graph layer for entity-relationship reasoning. Letta uses hierarchical context with vector-based recall. The pure patterns above are useful as building blocks, not as finished architectures.
5. The Hard Problems
The four patterns above handle the easy version of memory. The hard problems start where they end.
Identity Coherence
A user is not a list of facts. They're a coherent identity that emerges from hundreds of small details. The fact that they prefer brevity in emails, the way they joke, the topics they avoid, the projects they care about most. Storing these as discrete records loses the coherence between them.
This is the deepest unsolved problem in agent memory. We don't have a good representation for the gestalt of a person. The closest production systems get is by maintaining a free-form "user persona" block that the model itself writes and edits over time, similar to how MemGPT's core memory works. But this is fragile. The model can hallucinate. It can over-generalize from a single conversation. And there's no good way to measure whether the persona it has built actually matches the user.
Conflict Resolution
You said you were vegetarian last year. Last week, you mentioned eating shawarma. Which memory wins?
The naive approach is recency: newer memories override older ones. But this fails on stable facts that just weren't repeated. You might not have mentioned your sister's name in eight months, but she's still your sister.
Better systems classify memories by type before applying resolution rules. Identity facts (name, family relationships) have one set of rules. Preferences (favorite cuisine) have another. Temporary states (current project) have a third. The cleanest production approach uses an explicit invalidation step where new contradictory information doesn't overwrite old memories but supersedes them with a timestamp, leaving both in the store but only the current one visible at retrieval.
MemoryBank (Zhong et al., 2023) goes further and applies a forgetting curve modeled on the Ebbinghaus equation. Memories decay over time unless reinforced. This adds a temporal dimension that pure vector stores lack, though the choice of decay rate is essentially arbitrary.
Memory Decay
Some facts go stale. You changed jobs. You moved. You don't drink anymore. A memory system that never forgets becomes a liability over time. It will confidently surface outdated facts about you that no longer apply.
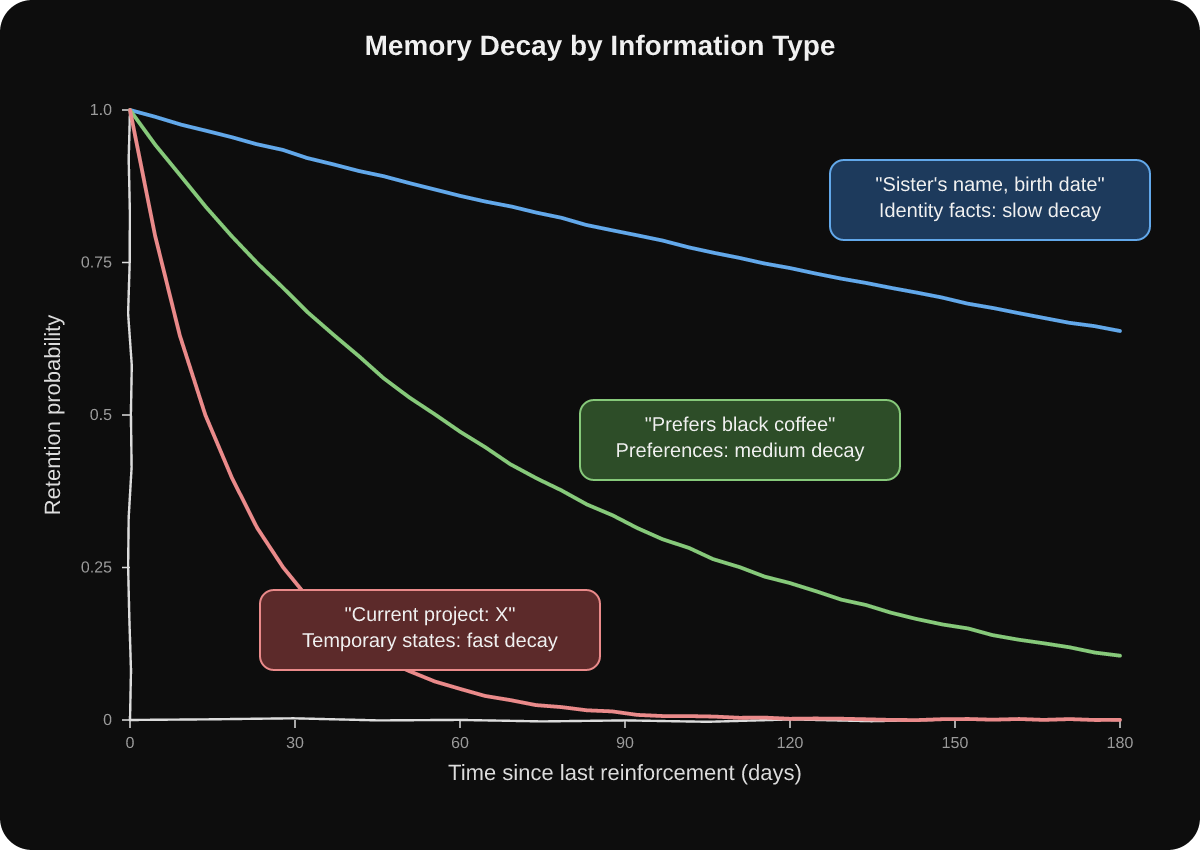 Figure 3: Different memory types decay at different rates. Identity facts (blue) stay reliable for months. Preferences (green) decay at a moderate rate and need periodic reinforcement. Temporary states (pink) collapse within days unless repeated.
Figure 3: Different memory types decay at different rates. Identity facts (blue) stay reliable for months. Preferences (green) decay at a moderate rate and need periodic reinforcement. Temporary states (pink) collapse within days unless repeated.
This is where the structured patterns have an advantage. A structured profile can be updated cleanly. The job field changes. The old value is gone. Vector stores, by contrast, accumulate. The old memory of your previous job is still there, still semantically close to questions about your career, still likely to be retrieved.
Production systems handle this with explicit retirement workflows. Periodically, the system reviews older memories and asks the LLM whether they're still likely to be true, demoting or deleting those that aren't. This is expensive but necessary for systems that need to stay accurate over years.
6. Real Systems Compared
It's worth grounding this with how production systems actually deploy these patterns.
ChatGPT Memory uses a structured profile approach with periodic summarization. The model decides what's worth remembering at the end of conversations and writes it to a memory store that's injected as system context in future sessions. Users can see and edit these memories directly.
Claude Projects takes a different approach. Memory is scoped to a project, not a user. Within a project, you can add knowledge files that are always available in context, and conversation history within the project is searchable. This is closer to a workspace metaphor than a personal memory system.
Mem0 is an open-source library that implements a hybrid pattern. It extracts facts using an LLM, stores them in both a vector database and a graph database, and exposes a simple API for adding and retrieving memories. The graph layer handles relational queries, the vector layer handles fuzzy semantic recall.
Letta (the company that built MemGPT) productizes the hierarchical memory pattern with explicit core memory, recall storage, and archival storage. Agents built on Letta manage their own memory through function calls.
The pattern across all four is consolidation. None of them rely on a single architecture. The flat-log pattern is the foundation, but it gets paired with extraction, summarization, or graph layers to handle the cases where pure semantic search breaks down.
7. What's Still Unsolved
This is the section that doesn't make it into product announcements. Memory in AI agents has real limitations that nobody has cracked.
The reliability problem. Memory systems based on LLM extraction inherit all the failure modes of LLMs. They hallucinate facts. They drop important context. They over-generalize from small samples. There's no clean way to verify what an agent "knows" about you, and no way to enforce that the memory matches reality.
The cold start problem. A new user has no memory. The agent has to be useful without context, and it has to figure out what context to ask for. Most systems handle this poorly, either being too pushy ("tell me about yourself") or too passive (no personalization at all until the system has accumulated enough signal).
The personalization-privacy tradeoff. The more an agent knows about you, the more valuable it is, and the more dangerous it is if it leaks or is misused. The architectures above don't really address this. They're optimized for capability, not for the user's ability to inspect, control, or revoke what's been stored.
The boundary problem. When does the agent's memory of you end? Memories from a work conversation shouldn't bleed into personal ones, but the architectures above don't natively distinguish. Scoping memory to contexts is mostly an unsolved interface problem, not a technical one, but it's where the field's current trajectory will hit real friction.
Closing
The illusion of memory in AI agents is built from very specific engineering choices. Strip away the marketing and you find one of four architectural patterns, or some hybrid of them, each making concrete tradeoffs about what gets remembered, how it's stored, when it's retrieved, and how it shapes the response.
None of these patterns is the answer. They're tools, and the right architecture depends on what your agent actually has to do. A simple Q&A bot needs a vector store and nothing more. A genuine long-running personal assistant needs something closer to the hierarchical model, with active memory management and explicit conflict resolution.
What's clear is that the memory layer is where the next wave of AI agent quality will be won or lost. Models are converging on similar capabilities. The differentiation moves to what surrounds them. And the system that knows you best, while staying accurate, current, and respectful of where its knowledge ends, is the system that becomes the assistant you actually use.
That system doesn't exist yet. But the pieces are all there. The work is in how you put them together.
Read more articles
Skills: How to Teach AI to Work the Way You Want
Skills: How to Teach AI to Work the Way You Want There's a simple idea that completely changes how you work with AI. It's called Skills . Here's the problem we all know too well. E...
April 28, 2026

What Happens When AI Agents Start Hiring Other Agents?
What Happens When AI Agents Start Hiring Other Agents? The next strange shift in AI will not be one agent doing everything. It will be one agent realizing it should not do everythi...
February 2, 2026
The Coming Wave of AI-Native Personal Tools
The Coming Wave of AI Native Personal Tools Most software today treats AI like a feature: a button in the corner, a prompt box, or a generated summary. But the more interesting fut...
March 13, 2025