
كيف يتعلّم الـ LLM مين انت: الذاكرة الدائمة في الـ AI Agents
كيف يتعلّم الـ LLM مين انت: الذاكرة الدائمة في الـ AI Agents
لما ChatGPT يتذكّر إنك نباتي، أو لما مساعدك الذكي يستحضر مشروع ذكرته قبل ثلاث أسابيع، تحسّ إنه في شي مختلف. النموذج يعرفك. هيك على الأقل يبدو الموضوع.
هاد المقال عن شو فعلاً يصير تحت السطح. لأن الحقيقة إن الـ LLMs stateless بالكامل. كل request توصل النموذج، من وجهة نظره هو، هي أول request شافها بحياته. ما في حالة محفوظة جوّا الشبكة العصبية. ما في خبرة متراكمة. ما في ذاكرة من امبارح.
كل اللي تحس فيه إن النموذج يعرفك، هو هندسة. الذاكرة في الـ AI Agents مش خاصية في النموذج. هي نظام مبني حواليه يصنع وهم متقن للاستمرارية.
هاد المقال يفكك هالنظام. رح نمشي على المشاكل الأربع الأساسية اللي أي معمارية ذاكرة لازم تحلّها، نقارن الأنماط الأربعة المهيمنة اليوم بكود حقيقي وتنازلات مقيسة، ونختم بالمشاكل الصعبة فعلاً اللي حتى الآن ولا حدا فكّها بالكامل.
1. مبدأ الـ Statelessness
عشان نحكي عن الذاكرة في الـ LLMs بصدق، لازم نكون دقيقين بشو يصير فعلياً.
النموذج اللغوي عبارة عن دالة (function). تعطيه تسلسل من الـ tokens، يرجّعلك توزيع احتمالات على الـ token اللي بعده. شغّل هاللوب وتطلع إجابة. النموذج ما يحتفظ بأي معلومة بين الاستدعاءات. اثنين requests لنفس النموذج من نفس المستخدم، الفرق بينهم خمس ثواني، ما في فرق بينهم من منظور النموذج نفسه.
اللي تحس فيه إنه محادثة متصلة، هو فقط الـ client يبعت تاريخ المحادثة كامل للنموذج كل دور. النموذج ما يتذكّر المحادثة. هو يقرأها من الصفر، كل مرة، ويتظاهر إنه يتذكر.
هاد منيح لمحادثة واحدة. الـ context window يستوعب التبادل كله. بس بمجرّد ما تخلص المحادثة، المحادثة هاي راحت من منظور النموذج. إذا بدّك المساعد يتذكّرك الأسبوع الجاي، أو الشهر الجاي، أو السنة الجاية، لازم تبني هالذاكرة برّا النموذج.
هون تبدأ الهندسة.
2. المشاكل الأربع الأساسية
أي نظام ذاكرة دائمة، مهما كانت معماريته، لازم يحل أربع مشاكل. غلطة بأي وحدة منهم، والوهم كله ينهار.
Extraction. شو يستحق التذكّر من المحادثة؟ كل كلمة؟ بس الحقائق؟ المشاعر؟ القرارات؟ التفضيلات؟ انت تعالج تيار من الـ tokens ولازم تقرر شو تكتبه. خزّن كتير وتغرق في الضوضاء. خزّن قليل وتفقد الأشياء المهمة.
Storage. بعد ما قرّرت شو تتذكّر، كيف تمثّله؟ نص خام؟ Embeddings؟ سجلات structured؟ Graph؟ كل خيار يجي معه عواقب. صيغة التخزين هي اللي تحدد شو نوع الاسترجاع ممكن لاحقاً.
Retrieval. لحظة ما تبدأ محادثة جديدة، كيف يعرف النظام أي ذكريات هي ذات صلة؟ ما تقدر تكب كل شي بالـ context window. تحتاج دالة تاخد الوضع الحالي وترجّعلك الشريحة الصحيحة من التاريخ. استرجاع غلط يعني النموذج إما يفوّت إشي مهم أو ينشغل بضوضاء غير مهمة.
Application. أخيراً، لما يصير عندك الذكريات الصح، كيف تحقنها في الـ prompt بدون ما تشوّش النموذج؟ الذكريات مش بس معلومات. هي سياق يشكّل كيف النموذج يفسّر باقي المدخلات. الطريقة اللي تأطّر فيها الذكرى تكون بأهمية الذكرى نفسها.
المشاكل الأربع مش مستقلة. قرار في الـ extraction يحدد شو ممكن في الـ retrieval. اختيار في الـ storage يقيّد استراتيجيات الـ application المتاحة. معماريات الذاكرة بأساسها هي عن كيف المشاكل الأربع تنربط ببعض.
3. الأنماط المعمارية الأربعة
رح نمشي على أربعة أنماط بترتيب التعقيد، من أبسط نهج انتاجي لأكثرهم تطوّراً.
النمط الأول: Flat Log مع Vector Search
هاد هو حصان الشغل. هو اللي يشغّل معظم ميزات "الذاكرة" اللي استعملتها. الفكرة مباشرة: خزّن كل تفاعل كقطعة نص، احوّل كل قطعة لـ vector، واسترجعها بالتشابه الدلالي وقت الحاجة.
 شكل 1: كل ذكرى تتحوّل لـ vector في فضاء عالي الأبعاد. الأسهم الملوّنة تمثّل أنواع ذكريات مختلفة، والأسهم الرمادية حوالين السهم الأزرق تمثّل ذكريات متشابهة دلالياً تتجمّع في نفس الاتجاه.
شكل 1: كل ذكرى تتحوّل لـ vector في فضاء عالي الأبعاد. الأسهم الملوّنة تمثّل أنواع ذكريات مختلفة، والأسهم الرمادية حوالين السهم الأزرق تمثّل ذكريات متشابهة دلالياً تتجمّع في نفس الاتجاه.
الـ extraction تافه. تخزّن كل شي، أو تخزّن ملخصات لكل محادثة. الـ storage هو vector database. الـ retrieval هو بحث k-nearest-neighbor. الـ application هو حقن أعلى النتائج في الـ prompt.
from openai import OpenAIimport chromadbclient = OpenAI()db = chromadb.Client().get_or_create_collection("user_memory")def remember(user_id: str, text: str, metadata: dict = None): embedding = client.embeddings.create( input=text, model="text-embedding-3-small" ).data[0].embedding db.add( ids=[f"{user_id}:{hash(text)}"], embeddings=[embedding], documents=[text], metadatas=[{**(metadata or {}), "user_id": user_id}] )def recall(user_id: str, query: str, k: int = 5) -> list[str]: query_emb = client.embeddings.create( input=query, model="text-embedding-3-small" ).data[0].embedding results = db.query( query_embeddings=[query_emb], n_results=k, where={"user_id": user_id} ) return results["documents"][0]def chat_with_memory(user_id: str, user_message: str): memories = recall(user_id, user_message) context = "\n".join(f"- {m}" for m in memories) response = client.chat.completions.create( model="gpt-4o", messages=[ {"role": "system", "content": f"You know the following about the user:\n{context}"}, {"role": "user", "content": user_message} ] ) return response.choices[0].message.contentنقطة القوة في هاد النهج إنه بسيط في البناء، سهل التوسعة، ويشتغل بشكل معقول من الصندوق. نقطة الضعف إنه ما عنده مفهوم للبنية. سؤال "وين يسكن المستخدم؟" و"بأي مدينة يسكن المستخدم؟" يمكن يرجّعوا ذكريات مختلفة تماماً. النظام ما يعرف إن هدول نفس السؤال. وما عنده طريقة يتعامل مع التناقضات. إذا قلت "أسكن في عمّان" قبل ست شهور و"للتو انتقلت لدبي" امبارح، الـ semantic search يمكن يرجّع الاثنين. النموذج بعدها لازم يكتشف لحاله مين الحالي.
استعمله لما: تحتاج تشغّل شي بسرعة، المحادثات طويلة ومتنوّعة، والاسترجاع التقريبي مقبول.
النمط الثاني: استخراج Profile مهيكل
بدل تخزين النص الخام، هاد النمط يستعمل الـ LLM نفسه لاستخراج الحقائق من المحادثات وصيانة profile مهيكل للمستخدم.
from pydantic import BaseModelfrom typing import Optional, Literalimport jsonclass UserProfile(BaseModel): name: Optional[str] = None location: Optional[str] = None occupation: Optional[str] = None dietary_restrictions: list[str] = [] communication_style: Optional[Literal["formal", "casual", "technical"]] = None interests: list[str] = [] current_projects: list[dict] = []EXTRACTION_PROMPT = """You are a memory extraction system. Given a conversation and the user's current profile,return an updated profile reflecting any new information learned. Only modify fields ifthe conversation provides clear new information. Return valid JSON matching the schema.Current profile:{profile}New conversation:{conversation}Return the updated profile as JSON."""def update_profile(profile: UserProfile, conversation: str) -> UserProfile: response = client.chat.completions.create( model="gpt-4o", messages=[{ "role": "user", "content": EXTRACTION_PROMPT.format( profile=profile.model_dump_json(indent=2), conversation=conversation ) }], response_format={"type": "json_object"} ) updated_data = json.loads(response.choices[0].message.content) return UserProfile(**updated_data)def chat_with_profile(profile: UserProfile, user_message: str): response = client.chat.completions.create( model="gpt-4o", messages=[ {"role": "system", "content": f"User profile:\n{profile.model_dump_json(indent=2)}"}, {"role": "user", "content": user_message} ] ) return response.choices[0].message.contentنقطة القوة هون هي الدقة. النموذج ياخد صورة نظيفة ومهيكلة عن المستخدم، مش كومة مزعجة من القصاصات المسترجَعة. ما في غموض حول شو يعرف النظام. التناقضات تتحل وقت الكتابة، لما الـ extractor يحدّث الحقل، مش وقت القراءة لما يضطر النموذج يوفّق بين ذكريات متضاربة.
نقطة الضعف هي الـ schema. لازم تقرر مسبقاً أي أنواع الحقائق تهم. إذا بدأ المستخدم يحكي عن شي خارج الـ schema، هاي المعلومة تضيع. وخطوة الـ extraction نفسها ممكن تهلوس وتستنتج "حقائق" المستخدم ما قالها أبداً.
استعمله لما: الـ use case ضيّق كفاية إنك تقدر تتنبأ بأنواع الحقائق المهمة، والدقة تهم أكثر من التغطية.
النمط الثالث: ذاكرة هرمية (نمط MemGPT)
Packer وزملاؤه (2023) قدّموا فكرة معاملة الـ context window في الـ LLM زي الـ RAM في نظام تشغيل. النموذج نفسه يقرر شو يبدّل للسياق العامل وشو يدفع للتخزين الأبطأ. هاي نُشرت كـ MemGPT ولاحقاً اتحوّلت لمنتج باسم Letta.
المعمارية فيها ثلاث طبقات. الـ main context هو اللي يشوفه النموذج كل request، فيها كتلة صغيرة من "الـ core memory" تحوي أهم حقائق المستخدم. الـ recall storage يحفظ تاريخ المحادثة اللي اتمسح من السياق بس لسا قابل للبحث. الـ archival storage للوثائق العشوائية والمعرفة طويلة المدى.
النموذج عنده وصول عن طريق function calling لهاي الطبقات. يقدر يعيد كتابة الـ core memory لما يتعلم شي مهم. يقدر يبحث في الـ recall لما يحتاج يتذكر محادثة سابقة. يقدر يكتب ويقرأ من الـ archival لما يشتغل مع وثائق.
CORE_MEMORY_TEMPLATE = """=== Core Memory ===[Persona]{persona}[User]{user_block}[Active Context]{active_context}"""TOOLS = [ { "type": "function", "function": { "name": "core_memory_replace", "description": "Rewrite a section of core memory.", "parameters": { "type": "object", "properties": { "section": {"enum": ["persona", "user_block", "active_context"]}, "old_text": {"type": "string"}, "new_text": {"type": "string"} } } } }, { "type": "function", "function": { "name": "recall_search", "description": "Search past conversations.", "parameters": { "type": "object", "properties": {"query": {"type": "string"}} } } }, { "type": "function", "function": { "name": "archival_insert", "description": "Store a piece of information in long-term archival memory.", "parameters": { "type": "object", "properties": {"content": {"type": "string"}} } } }]def agent_step(state: dict, user_message: str): system_prompt = CORE_MEMORY_TEMPLATE.format(**state["core_memory"]) response = client.chat.completions.create( model="gpt-4o", messages=[ {"role": "system", "content": system_prompt}, *state["working_messages"], {"role": "user", "content": user_message} ], tools=TOOLS ) return handle_response(state, response)نقطة القوة إن النموذج يصير مشارك فعّال في إدارة ذاكرته. يتعلم كيف يلخّص، يرتّب الأولويات، ويحدّث. هاد يتجاوز مشكلة الـ schema في النمط الثاني لأن النموذج هو اللي يقرر شو يستحق الحفظ، مش انت.
نقطة الضعف هي الموثوقية. النموذج ياخد قرارات إدارة ذاكرة كل دور، وهالقرارات تكلّف tokens و latency ومال. ممكن كمان ياخد قرارات سيئة، يكتب فوق سياق مفيد أو ينسى يكتب شي كان لازم يكتبه. الأنظمة الانتاجية المبنية على هاد النمط عادةً تضيف ضمانات: خطوات تأكيد صريحة، تدقيقات ذاكرة دورية، أو قيود schema على الـ core memory.
استعمله لما: تبني agent طويل الأمد ويحتاج فعلاً يتكيّف مع المستخدم على مدى شهور، وتقدر تتحمّل تكلفة الـ tokens الإضافية للذاكرة ذاتية الإدارة.
النمط الرابع: Knowledge Graph للذاكرة
هاد النمط يعامل الذكريات كـ graph من entities وعلاقات. Park وزملاؤه (2023) استعملوا نسخة من هاد في ورقة Generative Agents، الورقة الستانفوردية اللي حاكت بلدة صغيرة من شخصيات مدعومة بالـ LLM. كل شخصية تحتفظ بـ memory stream حيث كل ملاحظة تأخذ نقاط حسب الأهمية والحداثة والصلة، وأحداث التأمل (reflection) تركّب رؤى عالية المستوى من مجموعات الذكريات المترابطة.
النسخة الانتاجية لهاي الفكرة تستعمل graph database حقيقية. كل قطعة معلومة تصير node أو edge. الاستعلام في الـ graph يجوب العلاقات بدل البحث الدلالي.
from neo4j import GraphDatabasedriver = GraphDatabase.driver("bolt://localhost:7687")EXTRACTION_PROMPT = """Extract entities and relationships from this conversation snippet.Return JSON in the format:{{ "entities": [{{"name": ..., "type": ...}}], "relationships": [{{"from": ..., "type": ..., "to": ..., "metadata": {{...}}}}]}}Conversation: {text}"""def ingest(user_id: str, text: str): extraction = json.loads(client.chat.completions.create( model="gpt-4o", messages=[{"role": "user", "content": EXTRACTION_PROMPT.format(text=text)}], response_format={"type": "json_object"} ).choices[0].message.content) with driver.session() as session: for entity in extraction["entities"]: session.run( "MERGE (e:Entity {name: $name, type: $type, user_id: $uid})", name=entity["name"], type=entity["type"], uid=user_id ) for rel in extraction["relationships"]: session.run( """ MATCH (a:Entity {name: $from_name, user_id: $uid}) MATCH (b:Entity {name: $to_name, user_id: $uid}) MERGE (a)-[r:RELATES {type: $rel_type}]->(b) SET r += $metadata """, from_name=rel["from"], to_name=rel["to"], rel_type=rel["type"], uid=user_id, metadata=rel.get("metadata", {}) )def query_neighborhood(user_id: str, entity_name: str, depth: int = 2): with driver.session() as session: result = session.run( f""" MATCH path = (e:Entity {{name: $name, user_id: $uid}})-[*1..{depth}]-(related) RETURN path """, name=entity_name, uid=user_id ) return [record["path"] for record in result]نقطة القوة في نهج الـ graph إنه يلتقط بنية ما تلتقطها الـ embeddings الصرفة. حقيقة "سارة هي أخت المستخدم" و"سارة تشتغل في Google" تصير حقائق متّصلة. سؤال "وين تشتغل أخت المستخدم؟" يمكن الإجابة عليه بالتنقّل في الـ graph، حتى لو ما في رسالة سابقة تحوي هالصياغة بالضبط.
نقطة الضعف هي خطوة الـ extraction. تظبيط الـ entities والعلاقات صعب. نفس الشخص اللي ينذكر عبر محادثات مختلفة لازم يتم حلّه كنفس الـ node (مشكلة entity resolution). أنواع العلاقات تكبر بدون حدود إذا ما اتقيّدت. واستعلامات الـ graph ما تتدهور بسلاسة. إذا الـ graph ناقصها الـ edge الصح، ما تطلع بأي شي، لكن الـ vector search على الأقل يرجع بشي قريب تقريبياً.
استعمله لما: المجال فيه بنية علاقاتية واضحة تهم، وعندك ميزانية هندسية للتعامل مع entity resolution كما يجب.
4. مقارنة سريعة
| النمط | تكلفة الـ Extraction | جودة الـ Retrieval | يتعامل مع التناقضات | الأفضل لـ |
|---|---|---|---|---|
| Flat log + vectors | لا شي | تقريبي | بشكل ضعيف | بداية سريعة، تغطية واسعة |
| Profile مهيكل | استدعاء LLM لكل محادثة | دقيق | وقت الكتابة | مجالات ضيّقة، دقة |
| هرمي (MemGPT) | تكلفة LLM لكل دور | نشط | النموذج يقرر | Agents طويلة الأمد |
| Knowledge graph | استخراج ثقيل | مهيكل | عبر versioning | بيانات علاقاتية |
في الانتاج، أقوى الأنظمة عادة هجينة. Mem0 مثلاً يجمع vector store للاسترجاع الخام مع طبقة graph لاستدلال entity-relationship. Letta يستعمل سياق هرمي مع استرجاع قائم على vectors. الأنماط الصرفة فوق مفيدة كمكونات بناء، مش كمعماريات نهائية.
5. المشاكل الصعبة
الأنماط الأربعة فوق تعالج النسخة السهلة من الذاكرة. المشاكل الصعبة تبدأ من حيث تنتهي هاي.
Identity Coherence (تماسك الهوية)
المستخدم مش قائمة حقائق. هو هوية متماسكة تنبثق من مئات التفاصيل الصغيرة. حقيقة إنه يفضّل الإيجاز في الإيميلات، طريقة مزاحه، المواضيع اللي يتجنّبها، المشاريع اللي يهتم فيها أكثر. تخزين هدول كسجلات منفصلة يفقد التماسك بينهم.
هاي أعمق مشكلة ما انحلّت في ذاكرة الـ agents. ما عندنا تمثيل منيح للجِشطالت (gestalt) تبع الشخص. أقرب شي تقدر توصله الأنظمة الانتاجية هو الاحتفاظ بكتلة "user persona" مفتوحة الصياغة، النموذج نفسه يكتبها ويعدّلها مع الوقت، مشابه لكيف تشتغل الـ core memory في MemGPT. بس هاي هشّة. النموذج يقدر يهلوس. يقدر يبالغ في التعميم من محادثة وحدة. وما في طريقة منيحة لقياس إذا الـ persona اللي بناها فعلاً يطابق المستخدم.
Conflict Resolution (حل التناقضات)
قلت إنك نباتي السنة الماضية. الأسبوع الماضي، ذكرت إنك أكلت شاورما. أي ذكرى تربح؟
النهج الساذج هو الحداثة: الذكريات الأحدث تتجاوز الأقدم. بس هاد يفشل على الحقائق الثابتة اللي بس ما اتكرّرت. ممكن ما تكون ذكرت اسم أختك من ثمان شهور، بس هي لسا أختك.
الأنظمة الأفضل تصنّف الذكريات حسب النوع قبل تطبيق قواعد الحل. حقائق الهوية (الاسم، العلاقات العائلية) إلها مجموعة قواعد. التفضيلات (المطبخ المفضّل) إلها أخرى. الحالات المؤقتة (المشروع الحالي) إلها ثالثة. أنظف نهج انتاجي يستعمل خطوة إبطال (invalidation) صريحة، المعلومات المتناقضة الجديدة ما تكتب فوق الذكريات القديمة، بل تتجاوزها مع timestamp، يخلّي الاثنتين في المخزن بس بس الحالية تظهر في الاسترجاع.
MemoryBank (Zhong وزملاؤه، 2023) يروح أبعد ويطبّق منحنى نسيان مبني على معادلة إبنغهاوس (Ebbinghaus). الذكريات تتلاشى مع الوقت إلا إذا اتعزّزت. هاد يضيف بُعد زمني تفتقر له الـ vector stores الصرفة، رغم إن اختيار معدّل التلاشي هو إجباري بشكل اعتباطي.
Memory Decay (تلاشي الذاكرة)
بعض الحقائق تصير قديمة. غيّرت شغل. انتقلت. ما عاد تشرب. نظام ذاكرة ما ينسى يصير عبء مع الوقت. رح يقدّم حقائق قديمة عنك بثقة وهي ما عادت تنطبق.
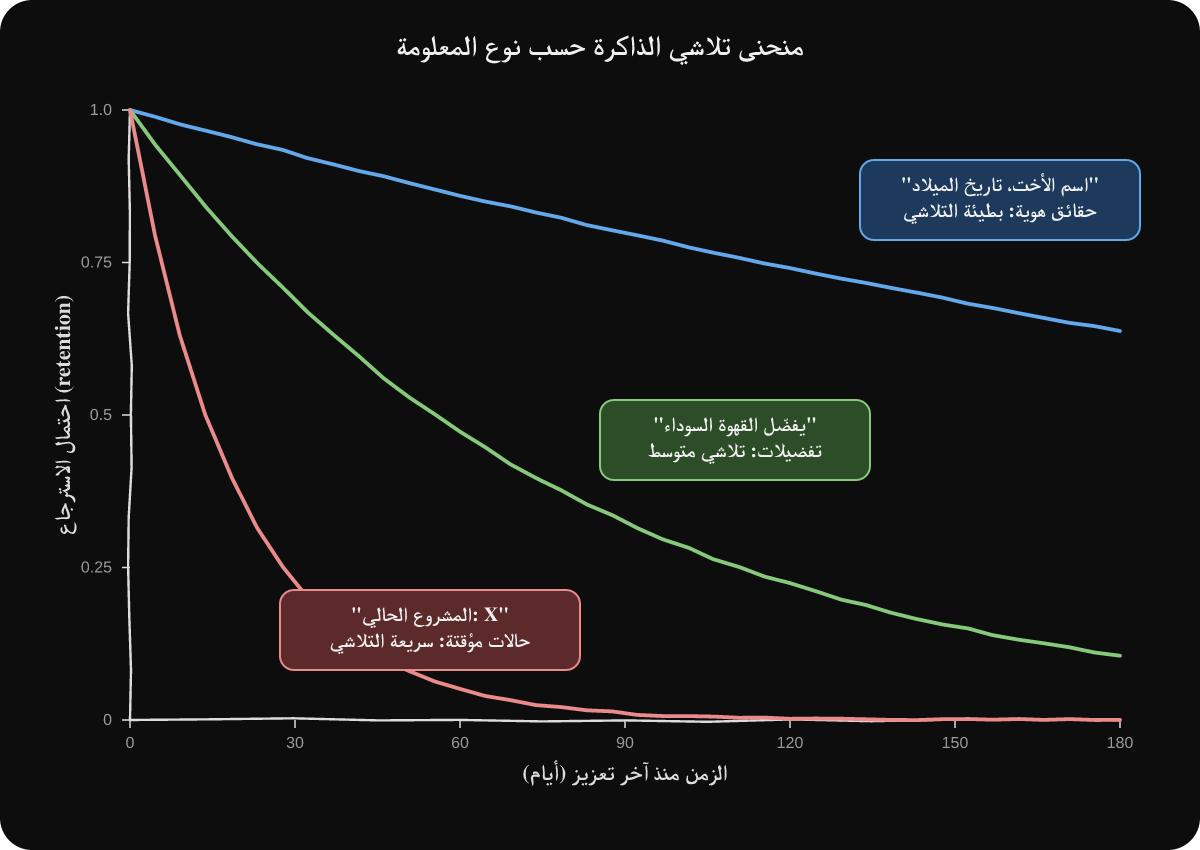 شكل 3: أنواع الذكريات تتلاشى بمعدّلات مختلفة. حقائق الهوية (أزرق) تظل قوية لشهور. التفضيلات (أخضر) تتلاشى بشكل متوسط وتحتاج تعزيز دوري. الحالات المؤقتة (وردي) تنهار بأيام لو ما تكرّرت.
شكل 3: أنواع الذكريات تتلاشى بمعدّلات مختلفة. حقائق الهوية (أزرق) تظل قوية لشهور. التفضيلات (أخضر) تتلاشى بشكل متوسط وتحتاج تعزيز دوري. الحالات المؤقتة (وردي) تنهار بأيام لو ما تكرّرت.
هون الأنماط المهيكلة عندها ميزة. الـ profile المهيكل يمكن تحديثه بنظافة. حقل الوظيفة يتغيّر. القيمة القديمة تختفي. الـ vector stores، بالعكس، تتراكم. الذكرى القديمة لشغلك السابق لسا موجودة، لسا قريبة دلالياً من أسئلة المسار المهني، لسا محتمل أن تُسترجع.
الأنظمة الانتاجية تتعامل مع هاد بـ workflows تقاعد صريحة. دورياً، النظام يراجع الذكريات الأقدم ويسأل الـ LLM إذا لسا محتمل أن تكون صحيحة، يخفّض أو يحذف اللي ما عادت كذلك. هاد مكلف بس ضروري للأنظمة اللي تحتاج تبقى دقيقة على مدى سنوات.
6. الأنظمة الحقيقية مقارَنة
يستحق أن نُؤصِّل هاد بكيف الأنظمة الانتاجية فعلاً تنشر هاي الأنماط.
ChatGPT Memory يستعمل نهج profile مهيكل مع تلخيص دوري. النموذج يقرر شو يستحق الحفظ بنهاية المحادثات ويكتبه لمخزن ذاكرة يُحقن كـ system context في المحادثات المستقبلية. المستخدمون يقدروا يشوفوا ويعدّلوا هاي الذكريات مباشرة.
Claude Projects ياخد نهج مختلف. الذاكرة مرتبطة بمشروع، مش بمستخدم. داخل مشروع، تقدر تضيف ملفات معرفة متاحة دائماً في السياق، وتاريخ المحادثة داخل المشروع قابل للبحث. هاد أقرب لاستعارة مساحة عمل من نظام ذاكرة شخصية.
Mem0 مكتبة مفتوحة المصدر تطبّق نمط هجين. تستخرج الحقائق باستعمال LLM، تخزّنها في كل من vector database و graph database، وتعرض API بسيط لإضافة واسترجاع الذكريات. طبقة الـ graph تعالج الاستعلامات العلاقاتية، طبقة الـ vector تعالج الاسترجاع الدلالي الضبابي.
Letta (الشركة اللي بنت MemGPT) تنتج نمط الذاكرة الهرمية مع core memory صريحة، recall storage، و archival storage. الـ Agents المبنية على Letta تدير ذاكرتها عبر function calls.
النمط المشترك عبر الأربعة هو التوحيد. ولا واحد منهم يعتمد على معمارية واحدة. نمط الـ flat-log هو الأساس، بس ينقرن مع طبقات استخراج، تلخيص، أو graph للتعامل مع الحالات اللي ينكسر فيها البحث الدلالي الصرف.
7. شو لسا ما انحلّ
هاد القسم اللي ما يوصل لإعلانات المنتجات. الذاكرة في الـ AI Agents فيها قيود حقيقية ولا حدا فكّها.
مشكلة الموثوقية. أنظمة الذاكرة المبنية على استخراج LLM ترث كل أنماط فشل الـ LLMs. تهلوس حقائق. تسقط سياق مهم. تبالغ في التعميم من عينات صغيرة. ما في طريقة نظيفة للتحقق شو "يعرفه" الـ agent عنك، ولا طريقة لفرض أن الذاكرة تطابق الواقع.
مشكلة الـ Cold Start. المستخدم الجديد ما عنده ذاكرة. الـ agent لازم يكون مفيد بدون سياق، ولازم يكتشف أي سياق يطلبه. معظم الأنظمة تتعامل مع هاد بشكل سيء، إما متطفلة كثير ("احكيلي عن حالك") أو سلبية كثير (لا تخصيص أبداً لحد ما يتراكم إشارة كافية).
مفاضلة التخصيص مقابل الخصوصية. كل ما الـ agent يعرف عنك أكثر، كل ما صار أكثر قيمة، وأكثر خطورة لو تسرّب أو أُسيء استخدامه. المعماريات فوق ما تعالج هاد فعلياً. هي مُحسَّنة للقدرة، مش لقدرة المستخدم على فحص أو ضبط أو إلغاء اللي اتخزّن.
مشكلة الحدود. متى تنتهي ذاكرة الـ agent عنك؟ ذكريات محادثة شغل ما لازم تنزف لمحادثات شخصية، بس المعماريات فوق ما تميّز هاد طبيعياً. تحديد نطاق الذاكرة بسياقات هي إلى حد كبير مشكلة واجهة مستخدم ما انحلّت، مش مشكلة تقنية، بس هون المسار الحالي للمجال رح يضرب احتكاك حقيقي.
الخاتمة
وهم الذاكرة في الـ AI Agents مبني من خيارات هندسية محددة جداً. شيل التسويق وتلاقي واحد من أربعة أنماط معمارية، أو هجين منهم، كل واحد يعمل تنازلات ملموسة حول شو يُحفظ، كيف يُخزَّن، متى يُسترجَع، وكيف يشكّل الاستجابة.
ولا واحد من هاي الأنماط هو الإجابة. هي أدوات، والمعمارية الصحيحة تعتمد على شو فعلاً لازم الـ agent يعمله. بوت أسئلة وأجوبة بسيط يحتاج vector store ولا شي أكثر. مساعد شخصي طويل الأمد فعلاً يحتاج شي أقرب للنموذج الهرمي، مع إدارة ذاكرة نشطة وحل تناقضات صريح.
اللي واضح هو إن طبقة الذاكرة هي حيث ستُربَح أو تُخسَر الموجة القادمة من جودة الـ AI Agents. النماذج تتقارب على قدرات متشابهة. التمايز ينتقل لما يحيط فيها. والنظام اللي يعرفك أحسن، مع البقاء دقيق، حديث، ومحترم لحدود معرفته، هو النظام اللي يصير المساعد اللي فعلاً تستعمله.
هاد النظام لسا ما موجود. بس القطع كلها هون. الشغل في كيف تركّبهم سوا.
اقرأ المزيد من المقالات
السكيلز: كيف بتعلّم الذكاء الاصطناعي يشتغل زي ما انت محتاج
السكيلز: كيف بتعلّم الذكاء الاصطناعي يشتغل زي ما انت محتاج في فكرة بسيطة بتغيّر طريقة شغلك مع الذكاء الاصطناعي بالكامل، اسمها السكيلز (Skills) . المشكلة اللي بنعرفها كلنا إنه كل ما...
28 أبريل 2026

ماذا يحدث عندما تبدأ وكلاء الذكاء الاصطناعي بتوظيف وكلاء آخرين؟
ماذا يحدث عندما تبدأ وكلاء الذكاء الاصطناعي بتوظيف وكلاء آخرين؟ التحول الغريب القادم في الذكاء الاصطناعي لن يكون وكيلاً واحداً يفعل كل شيء. بل سيكون وكيلاً يفهم أنه لا يجب أن يفعل ...
2 فبراير 2026
الموجة القادمة من الأدوات الشخصية المبنية حول الذكاء الاصطناعي
الموجة القادمة من الأدوات الشخصية المبنية حول الذكاء الاصطناعي معظم البرامج اليوم تتعامل مع الذكاء الاصطناعي كميزة إضافية: زر في الزاوية، صندوق prompt، أو ملخص تلقائي. لكن المستقبل...
13 مارس 2025